Introduction to RAGs

RAGs nowadays are very important models in the world of Large Language Models (LLMs) like ChatGPT and Gemini. They differ from these LLM models because LLMs can only generate human-like text and converse with you, but they can't provide much information about a document. In contrast, a RAG model first indexes a document you provide, allowing you to ask anything related to that document. Let's discuss this in detail.
What is RAG?
RAG stands for Retrieval-Augmented Generation. It is an advanced AI model that combines the ability to retrieve data from a document with text generation. Most LLMs are trained on pre-existing data and generate text based on that. However, with RAG, it first indexes the document or any input you provide, allowing you to ask the model anything, and it will give you answers related to that document.
Why RAG is used?
Access to recent information: LLMs have a cutoff date in their training data. RAG allows them to fetch the latest facts.
Domain-specific knowledge: You can connect RAG to private or custom datasets, like medical records or company documents.
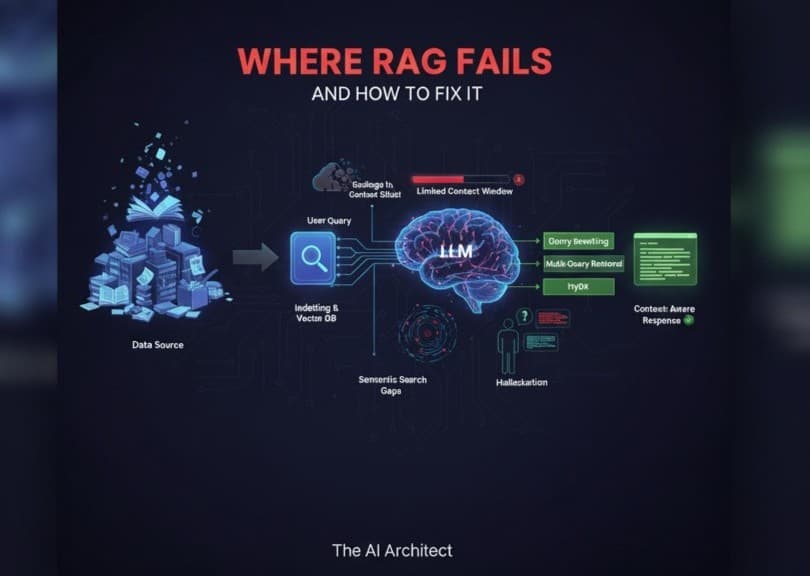
Reduced hallucinations: LLMs sometimes make things up. With retrieval, they rely on real documents for accurate answers.
Efficiency: Instead of training or fine-tuning a huge model repeatedly, RAG adds intelligence through external knowledge sources.
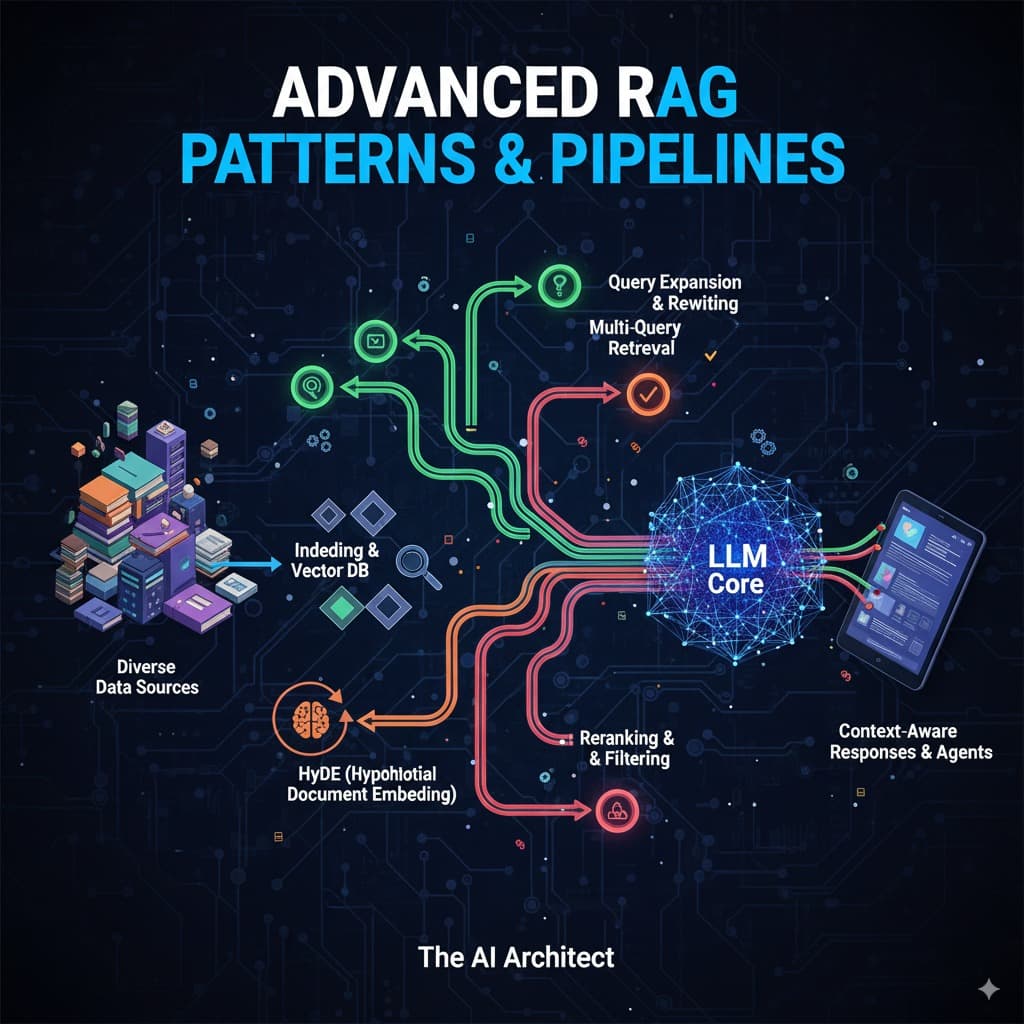
How RAG Works?
There are mostly two main parts in RAG:
- Indexing: First, we break our document into small chunks, then we convert these chunks into vectors and store them in our vector database.
Why Perform Vectorization?
Computers don’t understand text like humans do. Vectorization converts text into numerical vectors that capture meaning.
Example: “dog” and “puppy” will have similar vectors because they are semantically close.
These vectors allow the retriever to quickly find the most relevant text chunks when you ask a question.
Why Do RAGs Exist?
RAG exists because training a model with all possible knowledge is impossible—it would be too expensive and outdated quickly. Instead, RAG gives models a dynamic way to connect to external knowledge sources, keeping them flexible, lightweight, and up-to-date.
Why Perform Chunking?
When storing large documents, it’s not efficient to search entire books or articles. Chunking breaks documents into smaller, meaningful pieces (like 200–500 words each).
This makes retrieval faster.
Improves accuracy because the retriever can return only the most relevant passage.
So I want to conclude by saying RAG bridges the gap between regular LLMs and dynamic real-world knowledge. It helps us grasp that knowledge from documents, websites, your own text, and many more sources, providing us with the text we seek. These are the models currently in demand in the market, which many businesses want for themselves.