RAG Advanced Patterns and Pipelines.
Before we explore advanced RAG patterns and pipelines, let’s quickly revisit what RAG is, why it matters, and what makes it so widely discussed.
Retrieval-Augmented Generation (RAG) is a technique that pairs large language models (LLMs) with a retrieval system. While LLMs are powerful, they’re limited to the data they were trained on and can’t inherently access your custom or domain-specific information. RAG bridges that gap by pulling relevant information from your own data sources and providing it to the model, enabling more precise and context-aware answers.
A Quick Look at How RAG Works
Indexing: Your data is first divided into smaller sections (chunks) and transformed into vector embeddings — mathematical representations of text. These embeddings are stored in a vector database for efficient searching.
Query Embedding: When a user submits a question, the query is also converted into an embedding, allowing the system to compare it against the stored data.
Retrieval and Response Generation: The system finds the most relevant chunks based on the query, retrieves them, and feeds them to the LLM. The model then uses this information to craft a tailored, context-rich response.
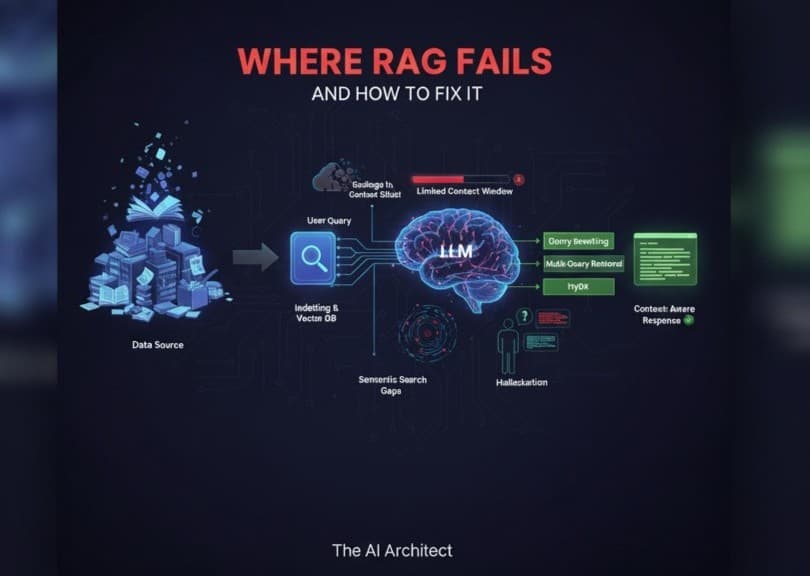
Why we need advanced patterns and pipelines:
We encountered several issues with RAG models, which led us to the need for advanced patterns and pipelines. These issues included:
1. Poor Input, Poor Output:
An LLM can only work with the information it’s given. If a query is unclear, nonsensical, or riddled with spelling mistakes (e.g., “asasasaass”), the system may produce equally poor results. Ambiguous prompts lead to vague or irrelevant answers.
2. Context Window Limitations:
Every language model has a fixed context window — the maximum amount of text it can process at once. If the query and retrieved documents exceed this limit, the model may miss important details or fail to give a well-rounded response.
3. Gaps in Semantic Search:
Even advanced vector search methods aren’t perfect. They may overlook subtle yet important pieces of information, especially when the dataset is large or the query is nuanced. This can lead to answers that are technically correct but incomplete.
4. Challenges in Domain Reasoning:
Words can take on very different meanings across industries — “bond” in finance vs. chemistry, for example. Without deep domain-specific knowledge, LLMs may misinterpret terms and deliver overly simplified or incorrect conclusions.
5. Hallucinations:
One of the biggest challenges in AI today is hallucination — when a model confidently generates content that isn’t accurate. This often happens when the LLM doesn’t have enough context, causing it to “fill in the blanks” with made-up details.
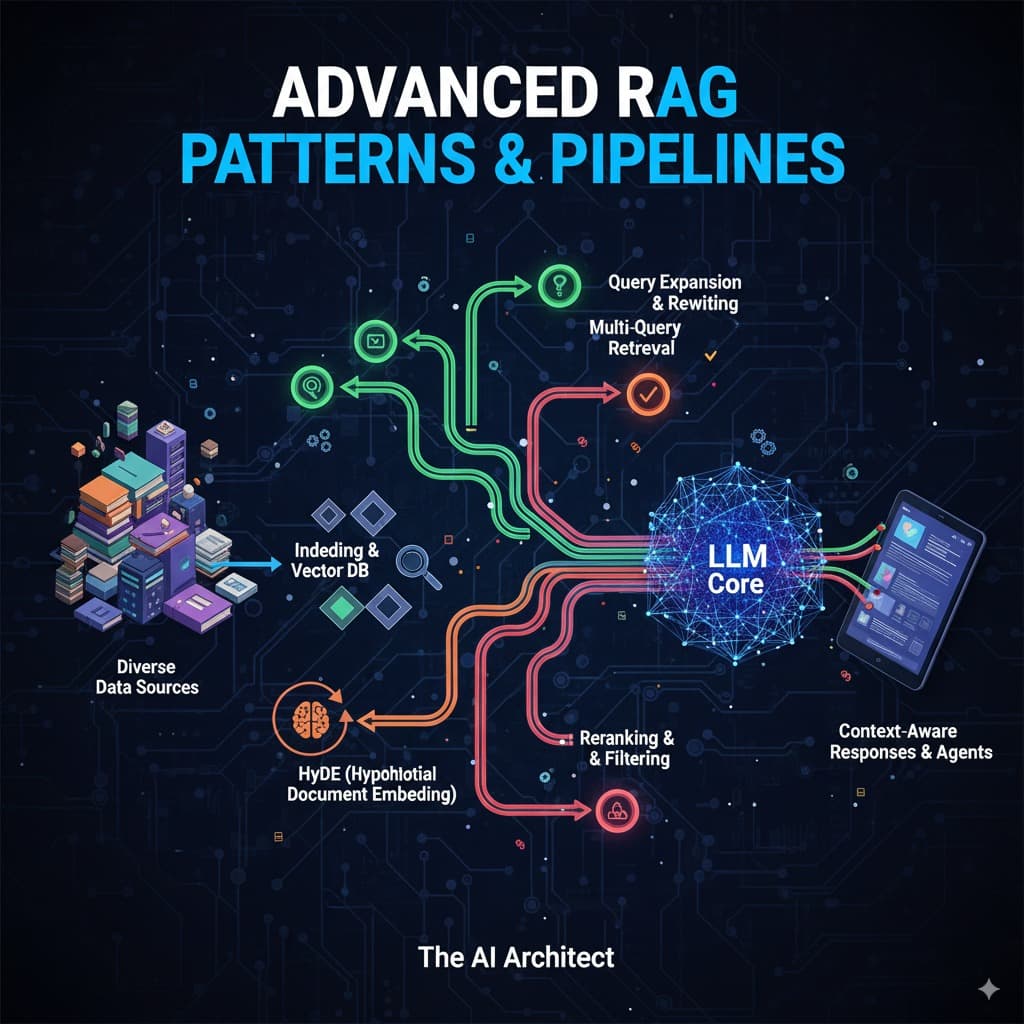
Advanced patterns and pipelines:
To address these limitations, we use advanced RAG patterns and pipelines designed to improve retrieval precision and output quality:
1. Query Rewriting:
LLMs can rephrase and refine user queries to make them clearer and more precise, helping the RAG system better interpret intent and return more relevant data.
2. Multi-Query Retrieval:
Instead of relying on a single query, this method creates multiple variations of the same question. Documents are retrieved for each variation, scored, and ranked, ensuring the system surfaces the most relevant and comprehensive information.
3. HyDE (Hypothetical Document Embedding):
Rather than searching directly with a raw query, HyDE generates a hypothetical answer first. This answer is embedded and used to search the vector database, often producing deeper, context-rich results.
4. Re-Ranking with Cross-Encoders:
After retrieving initial results, a cross-encoder model can re-rank them based on semantic relevance, further improving accuracy. This extra layer of ranking helps prioritize the most useful information for the LLM.
5. Iterative Retrieval (Feedback Loops):
Some pipelines use a loop where the LLM analyzes initial results, refines the query, and searches again. This iterative approach can help uncover data that might have been missed in the first pass.
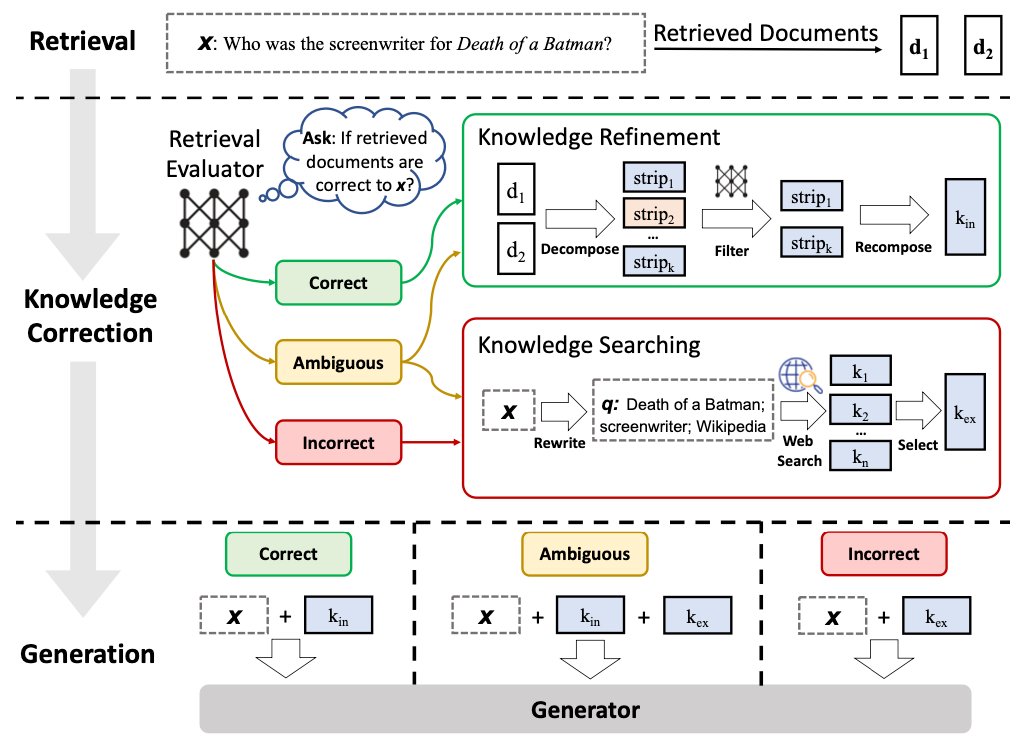
In conclusion, I would like to add: Advanced RAG patterns and pipelines are pushing retrieval-augmented systems far beyond their basic form, making them smarter, more context-aware, and capable of handling complex, domain-specific use cases. By combining techniques like query rewriting, multi-query retrieval, HyDE, re-ranking, and iterative feedback loops, we can significantly boost both accuracy and reliability.
As LLMs continue to evolve, so will RAG — with trends like agent-based retrieval, dynamic context management, and multimodal search on the horizon. For now, experimenting with these advanced strategies is the best way to build RAG systems that feel less like static tools and more like powerful, adaptive assistants.