Where RAG Fails?
Before diving into where RAG fails, let’s first understand what it is, why it’s important, and why there’s so much hype around it.
RAG stands for Retrieval-Augmented Generation. In simple terms, it combines large language models (LLMs) with a retrieval system. While LLMs are trained on vast amounts of general data, they often struggle when you need them to work with your own private or domain-specific data. This is where RAG comes in — it retrieves relevant information from your data sources and feeds it into the LLM, enabling it to generate more accurate and context-aware responses.
How RAG Works:
RAG operates in three main steps:
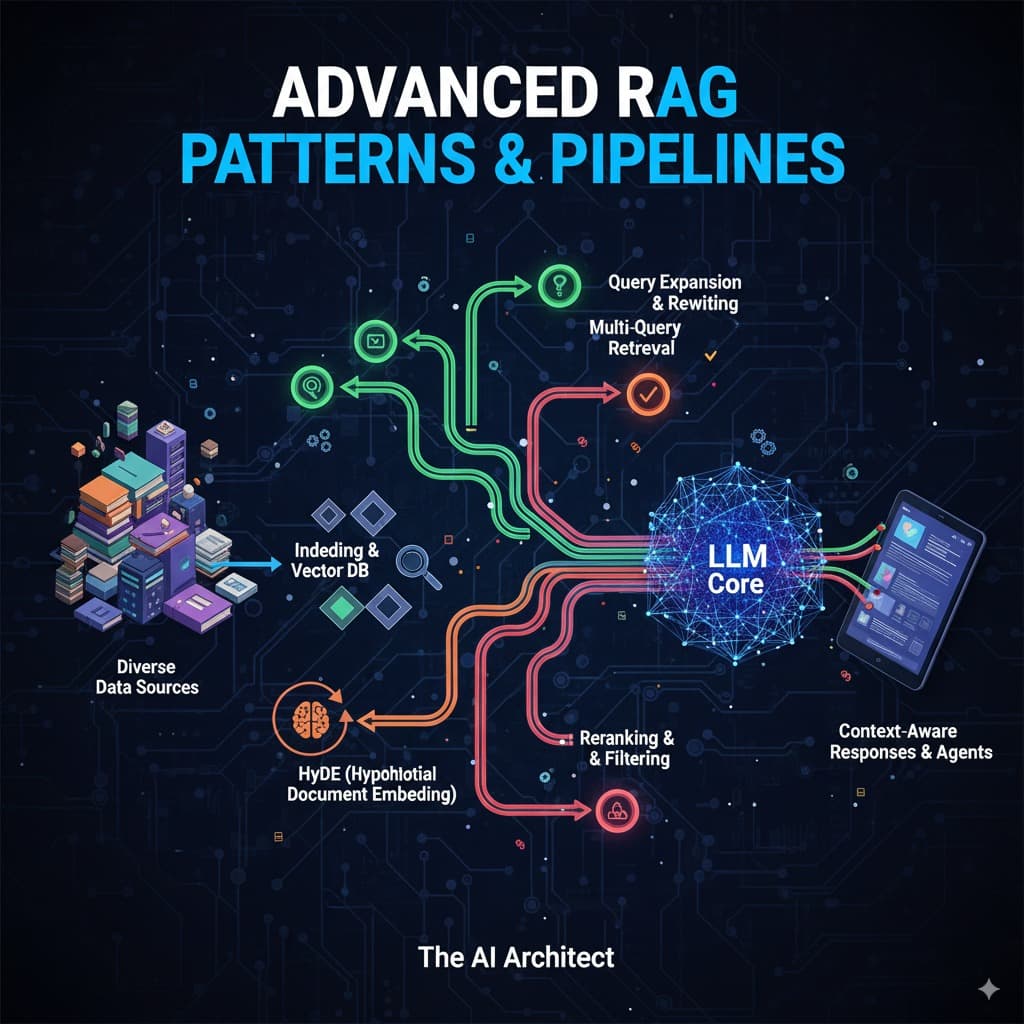
Indexing: First, you provide your data to the system. The data is broken down into smaller, manageable chunks, and then each chunk is converted into vectors (numerical representations). These vectors are stored in a vector database for quick retrieval later.
Query Vectorization: When a user submits a query, the system also breaks it down and converts it into a vector representation, making it easier to compare with the stored data.
Retrieval & Generation: The system searches the vector database for the most relevant chunks (usually two or three) that match the query. These chunks are then passed to the LLM, which uses them to generate a context-aware response for the user.
Core RAG Limitations:
Let’s Now Discuss the Core limitations of RAG:
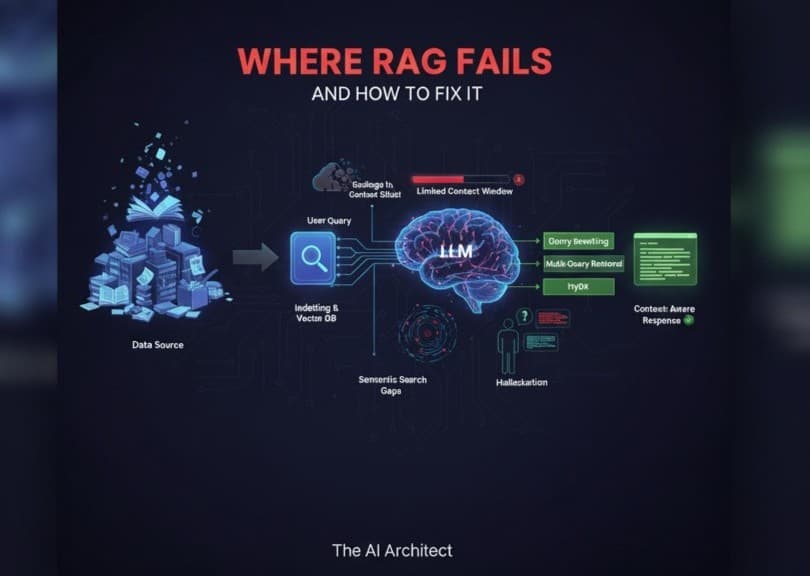
Garbage In, Garbage Out: If a user gives an LLM a poorly structured or nonsensical query — like random text (“asasasaass”) or a query filled with spelling and grammar mistakes — the model is likely to produce poor-quality or meaningless responses. An unclear question often leads to a vague answer.
Limited Context Window: Every LLM has a maximum context window (the amount of text it can process at once). If a query, along with retrieved information, exceeds this limit, the model may not fully understand the question or provide a complete, contextually accurate response.
Semantic Search Gaps: LLMs can sometimes skip important information that’s relevant to a query. This issue often appears when the model’s context window is already full, making it harder to retrieve and present all necessary details accurately.
Domain-Specific Reasoning: LLMs may struggle to reason in specialized fields. In different domains, the same word can carry different meanings. Without deep domain understanding, the model may misinterpret context or provide oversimplified answers.
Hallucination: Many LLMs occasionally “hallucinate,” meaning they generate confident but incorrect information. For example, if a user asks about a topic and the model lacks sufficient context, it might invent details or rely on irrelevant information from earlier parts of the conversation.
Solutions to conquer these failures:
Query Rewriting: Using LLMs to rewrite user queries improves their clarity and precision, helping the RAG system retrieve more relevant data.
Multi-Query Retrieval: Instead of relying on a single rewritten query, we can generate multiple query variations using LLMs. The system retrieves documents for each variation, then ranks the results by relevance, ultimately providing the user with the highest-ranked, most relevant information.
HyDE (Hypothetical Document Embedding): Rather than searching the vector database directly with the user’s original query, we first ask the LLM to generate a hypothetical answer. We then embed this hypothetical response and use it to search the database. This often yields more accurate and contextually relevant results.
RAG is a powerful technique that extends the capabilities of large language models, making them more useful for domain-specific tasks and real-world applications. But as we’ve explored, it’s not a magic solution — it comes with limitations like context window size, retrieval quality, reasoning challenges, and hallucinations. The good news is that techniques like query rewriting, multi-query retrieval, and HyDE can significantly improve its performance. The future of RAG lies in combining smarter retrieval strategies with reasoning-focused AI systems, making responses not just more accurate but also deeply contextual.